

Predicting Unpredictable Bugs & Testing Distributed Systems
Or, "No-One Expected Dennis Nedry But Maybe Could Have Better Prepared For His Actions"
Dr. Ian Malcolm
For most people, Jurassic Park was the first time they'd been exposed to the term "Chaos Theory":
Malcolm: "You see? The tyrannosaur doesn’t obey set patterns or park schedules. The essence of Chaos."
Ellie: "I’m still not clear on Chaos."
Malcolm: "It simply deals with unpredictability in complex systems. The shorthand is the Butterfly Effect. A butterfly can flap its wings in Peking and in Central Park you get rain instead of sunshine." – Jurassic Park (1993)
Chaos theory states that small changes in complex systems can have big, unpredictable effects. Although not a small change, Dennis Nedry's actions were unforeseen, they brought about dire consequences.
Chaos theory says that when you deal with very complicated situations, unexpected things are going to happen. When you build software, even the simplest of applications bring a seemingly disproportionate amount of hidden complexity.
What chaos theory tells you is that you cannot predict very far ahead successfully. You have to expect things to fail, and you’ve got to be ready to change. This might sound terrifying, but on the other side of the coin; freeing. Trying to control every single unpredictable outcome in a system is unrealistic and fruitless. Rather, aim to relinquish that control and instead concentrate on building awareness and confidence in your system, making flexibilty and resilliency your new targets. A better, healthier way to look at it is: complex systems will produce unpredictable and unexpected effects, so accept failure as inevitable but employ practical methods to gracefully handle the fallout.
Testing 101: Why?
The aim of testing is essentially to avoid and reduce bugs, which leads to us having more confidence that our system will behave in the ways we expect. Notice I said "more confidence", not "total confidence". Perfection is a myth and unattainable.
In practical terms, there's two main objectives for testing:
Maintaining data integrity
The data within a system is the golden source of truth for how our system will treat a customer, it's also permanent (to a degree), so allowing contaminated data into our databases is setting ourselves up for a bad time. It's often subtle and insidious when bad data is stored, and it's often harder to recover from.
Upholding an acceptable user experience
We'll never reach the nirvana of catching every bug before it hits production, but we want to reduce the chances of a customer finding a bug as much as we can. It leads to a poor user experience and might deter a customer from returning. If we look at our system in two distinct parts: data and state. The state of a system can often be easier to recover from without much (if any) lasting damage. As long as bad data wasn't stored, we can usually restart a process that's stuck or crashed, and the user can retry an action. While less damaging in the long run, we'd still rather avoid this subpar experience.
Knowing your system
Proof is in the pudding
One devishly straightforward method of building confidence in your system is to prove its behaviour.
Identifying key methods and critical functionality, whether in terms of importance or complexity, is the first part of the puzzle. This logic should ideally be extracted into pure, isolated functions, which can then be unit tested.
We want minimal-effort, high-value testing. Identifying the critical flows a user or data will take through our system is paramount. If we're dealing with a distributed system, that can be mighty tricky to test. To keep things extremely practical, identify API endpoints in your system that 1) are critical to the functionality of your system (creating users might be one) and 2) if requested, will touch many services in your system. By doing this, you're proving the functionality of multiple services, methods and processes in one API request. You can trigger this request programmatically and assert the response is what you expect it to be.
Being able to run your system in an isolated, controlled and ephemeral environment is going to be hugely advantageous and make possible the sort of end-to-end test mentioned above.
Functionality transparency
The more awareness you can build, the better chance you have to foresee and guard against unexpected outcomes.
We have to strike a balance between DRY, reusable code and too many layers of abstraction. Too many layers of abstraction tend to make the system hard to reason about, increases cognitive load and therefore makes it harder to spot hidden complexity. Any hidden complexity has the possibility of unexpected results. You can hide an awful lot of unwieldy functionality behind a neatly exposed interface.
Tribal knowledge
In theory, no-one knows the intention, context or inner workings of a piece of code better than its author (in theory). Unless documented sufficiently, this can lead to fragmented, system-wide information and context living inside multiple engineer's brains. I may know Service A like the back of my hand, and you may know Service B extremely well, but unless we coordinate, a subtle behaviour from Service A might have unforeseen impact on Service B's functionality.
Everyone knows developers love writing docum-hang on, sorry, hate writing documentation. It's key to foster a flexible, low-friction, easy-to-maintain method for developers to extract and record the subtleties of their own code. This might be a "User Manual" section in a Service's README.md, or it might be an attached walkthrough recording in a PR - whatever suits your team, it just has to be consistent, visible and kept up-to-date.
Unexpected side-effects
One part of a system directly calling another part of a system is fairly straightforward to reason about. As soon as we introduce asynchronous operations, background queues, events or any other type of patterns commonly utilised in distributed systems, we increase the cognitive load required to parse a piece of code or functionality just by looking at it.
More crucial documentation in a distributed system is mapping out inter-service communication and their dependant interactions.
This might look like:
SERVICE A
Broadcasts: USER|CREATED, USER|REMOVED
Listens for: PASSWORD|GENERATED
SERVICE B
Broadcasts: EMAIL|SENT
Listens for: USER|CREATED, USER|REMOVED
Unknown unknowns
"…there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns - the ones we don’t know we don’t know." – Donald Rumsfeld
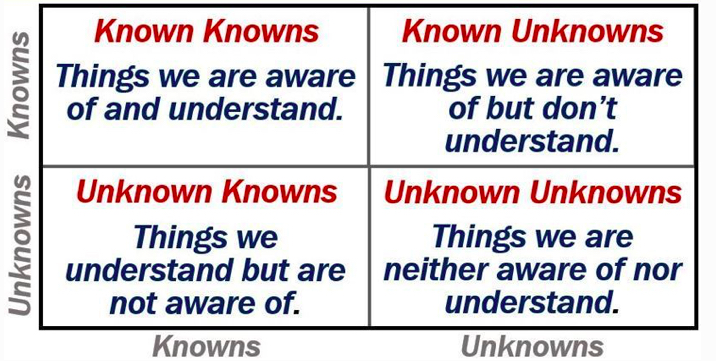
In a complex distributed system, there are complexities in functionality we are aware of and also understand - so we write tests and can predict the outcomes fairly confidently - this is the top left quadrant, the green, safe zone. The more functionality we can keep in this zone, the better.
Anything outside of this quadrant poses a potential risk we need to spend time mitigating (or at least increasing our understanding so we know exactly how much mitigation is necessary)
Three of the main issues arising from the more nefarious quadrants can be categorised in the following way:
Lack of awareness
It's likely the developer is not aware of a vulnerability and how much of risk represents. You can't begin to figure out a fix for something you have no idea exists, let alone whether it might poses future problems.
To remedy this, we need to build awareness of the system we're working in. Three solid way to begin this process are as followed:
- Fix an existing bug - it might not be immediately obvious which part of the system to begin debugging in, so it can be a beneficial adventure down a rabbit-hole which only leads to greater understanding along the way.
- Add functionality - Pick a feature which will require end-to-end changes, i.e. from database -> API. Add a new column to a data store and expose it via the API, which (likely) requires touching various files, methods and schemas.
- For new codebases - Set the codebase up locally, strictly following the steps in the README. Amend the README with missing or incorrect steps for the next developer. This is a handy way to not only increase understanding, but also keeps documentation synced with the actual system. This can also be a good way to tighten up the experience for new hires; periodically delete your local codebase and environment, and re-clone your remote repository, following the README as above.
Faulty assessment
The developer is aware of vulnerability but doesn’t understand its potential impact. Mildly better in that we can see a potential bug, we just don't understand the blast radius it would have if it blew up.
Homework time! Get to know the existing functionality or solution as much as you can, which may be reading 3rd party, and often internal, documentation. Speak to the original author of the code if possible.
If that's not possible, and you've inherited some code you don't understand, try as best you can to simplify the existing solution. That may be rewriting it, or even reworking that flow within the system. A powerful wand is deadly in the wrong hands (see: Voldemort), so if you're struggling to understand the magic, restrict yourself to using a less powerful wand.
Inability to act
The developer is aware of vulnerability but doesn’t have the skill or know-how to address it. In this frustrating scenario, you're often left with trying to contain the blast radius if it does blow up. This is often achieved by isolating the negative path or impact of the complex functionality as best you can. You may not understand how to address the vulnerability itself, but you may be able to limit the collateral damage.
Initial system design
Conscientious developers are unlikely to ignore known potential bugs, so we have to presume a baseline of developer morality here. Just by reading this, I will presume you exceed that baseline.
Premature optimisation vs future-proofing
Scaling issues are a Good Thing, because it means your system is getting more usage than it's been designed for, but there's little value in spending copious time and effort implementing a highly-scalable system for zero users. Spend more time and effort attracting the users to your system, which doesn't mean ignore scaling entirely until you've hit that capacity. Try designing the system with flexibility and scale in mind, but save the implementation effort until it's time. Then it's simply a case of dialling up those knobs, or making minor code changes, to activate the previous future-proofing work you did.
Moving fast in the right direction
We'd all love to build the Perfect system, but 1) that doesn't exist 2) it won't fit your needs. Instead, establish the high-value needs for your system upfront and aggressively design the system with those needs at the forefront.
A shopping list app is going to have vastly different needs than a real-time chat app which is going to have vastly different needs than a medical platform with highly-sensitive patient information. Most applications have a baseline need for performance, availability, security and data integrity, so figure out which of those to skew your system design towards.
Quantified risk
Building awareness of your system will give you the option of coming back to a potential bug at a later date.
For example, it's a great idea to build a library to DRY up and centralise your data access methods (i.e. database connection, querying, etc). It's also a good idea to impose an implicit default LIMIT to all SELECT queries, i.e. 100 rows max, which would be implicitly set by the library and exposed as a .find() method.
This took very little time and effort and keeps scaling needs in mind when designing the library. However, it's extremely likely we'll have scenarios where we want to return more than 100 rows in the future. Knowing your system inside out, and monitoring its usage, will let you know when it's time to build pagination into your data access library.
This has kept our system future proofed, but we didn't fall into the premature optimisation trap.
Netflix chaos monkeys
"We created Chaos Monkey to randomly choose servers in our production environment and turn them off during business hours" - Netflix Technology Blog
Simulating negative scenarios
Why would we want to intentionally break our system? Because we'd rather uncover that weakness by stress-testing our system, vs. letting a customer happen upon it themselves.
Here's a starter point:
- Replicate a DDoS attack with nefarious use of the
loopin your favourite language - Set an obnoxiously high iteration count
- Hammer your method or interface
- Record the point it starts to slow and strain
- Record the point it crashes and times out
- Use those findings to refactor your code and improve performance for specific scenarios, vs blindly refactoring for unknown performance targets
- Use those break points as an opportunity to gracefully handle timeouts and crashes in your system
Guarding against them
If a key component in your system dies, make sure bad data can't make its way into your data stores. We can alleviate this by ensuring we have strict data validation at the data model level (at the point the data would be inserted or updated in a database).
Make sure you have readily-accessible, well-documented ways for engineers to recover parts of the system that have fallen into an irrecoverable state, i.e. a runbook containing exact steps to access, for example, the production Kubernetes cluster, which kubectl commands to run, etc...
If the system has been designed with flexibility in mind, it should be relatively safe to allow engineers to restart parts of the system with ease.
Testing in production
audible gasp...
There's a very short list of operations that can truly only be tested in production.
Making a payment with real money is on that very short list. However, we want to be sure we've covered as much pre-production ground as possible. We should be utilising sandbox environments from 3rd party APIs, testing all the various flows and responses we may receive.
Hammer every single negative scenario and sad path for the relevant and surrounding functionality regarding the payment:
- What happens if the payment fails?
- Does the user know?
- Are corresponding account balances incorrectly updated?
- Can the payment be retried?
Think Production
Design your functionality with multiple instances in mind:
- If 3 versions of my code were running simultaneously, would 3 payments be made?
- What mechanism decides which instance processes the payment operation?
- If the payment succeeds, are 3 events broadcast through the system?
Exposing weaknesses and brittleness
Rarely does a user use your system 100% in the way it was intended. We create these scenarios under controlled, isolated environments so we can stress-test our functionality in ways we might not have considered when building it.
Happy vs sad path
Most engineers build functionality to cater for the happy path, i.e. the way the code will operate if it's executed the way it's been expected and designed for, and produces the behaviour the engineer expects.
However, most engineers (hi) neglect the sad path, i.e. the branches of code that should handle validation errors, timeouts, instance crashes, loss of database connection, loss of network connection, etc. It's less fun and quite frankly; it's boring.
Pop quiz, hotshot: sprinkle in some random throw new Error()'s into your code and see what happens. Was the error handled gracefully? Did subsequent operations continue to execute when maybe they should't have?
Atomic operations
If an error is thrown in operation A, should B continue to run, or should the entire flow bail, or was A's failure acceptable in the bigger picture?
Working scenario:
If a user signs up to our system, we want to send them a welcome email and also insert them into the database. We likely don't want to prevent the database insertion if the email failed to send.
Two ways we can improve this:
Isolated error handling - If the email fails to send, contain the failure, log the error, continue to insert the user into the database.
Make it all asynchronous - Set a listener in the email-sending-part of the system to send an email whenever it receives a USER|CREATED event. Insert the user into the database immediately after signup. Broadcast a USER|CREATED event asynchronously, this allows you to respond back to the user signing up vs. waiting for the email to send.
Rollbacks, Migrations & Restarts
If your system has found itself to be in a bad state, you normally have 3 options depending on what bad state it's in:
A bug has found its way into the latest deployment -
- Rollback to a previously working deployment
- If the bug-ridden deployment changed database schemas, ensure your database migrations are set up correctly to rollback the schema changes
- Fix the code bug and re-deploy
Bad data has made its way into a database -
- Cleanse the data manually
- Plug the code gap that allowed for the contamination to occur
Parts of the system are unresponsive, "stuck", crashing, or timing out
- "Have you turned it off and on again?"
- Simply restart the stuck process (i.e. if using Kubernetes, kill the naughty pods in question and they'll be recreated and hopefully behave better)
...Ok, you killed the naughty process, but it's stuck in a crash loop on startup, what now?
- A bug was recently introduced? Find it and destroy it
- Production configuration recently changed? Audit the current config for changes, i.e. a database URL might need updating to a new host
The naughty process itself would be working fine, but it's dependent on a downstream service being available:
- Decide if the downstream service is 100% crucial to the operation of the aforementioned naughty process
- If it is: handle the crash/error gracefully, put the system in maintenance mode to avoid bad data leaking in and let customer's know what's happening
- If it's not: log the error then wrap the downstream service connection code in tighter isolation, one that doesn't allow for such widespread chaos if it breaks
Finding comfort in the discomfort
Assessing acceptable risk
Each system will have different needs; spend acceptable time optimising for the higher-priority needs.
Assess which sad paths can be revisited at a later date and which need addressing upfront in a future-proofing fashion.
Protect the data stores at all costs from bad data finding its way in. Bad state can be recovered fairly easily; bad data is harder to track down and recover from.
Graceful error handling
A system shouldn't completely melt if one of its components dies. Design with resiliency in mind; paying close attention to how services communicate and how each dependent service behaves if a downstream service fails to respond or crashes.
Atomic operations
Decide which are the mission critical steps in any given user or data flow in your system.
Losing a user's signup information because a welcome email failed to send is Not Good. Bailing an entire flow because a critical step has failed is a good idea, especially if the flow can be retried idempotently.
Hold onto your butts
Remember, no-one wants to be sat trying to debug two million lines of code while production is on fire...or dinosaurs are escaping.
No-one saw Dennis Nedry coming, but maybe allowing an entire system to live inside one developer's brain with no documentation in sight could have been avoided. Maybe expense had been spared...
